")

Overview
- The PSC is a general purpose framework for simulating grid and particle based numerical models on multi-threaded heterogenious computational platforms. It has been shown to scale up to a few hundred thousand threads on architectures like the IBM BlueGene super-computer, the SuperMUC at the LRZ in Garching, the Stampede super-computer at the University of Austin or similar architectures. The performance of the PSC code scales weakly and strongly with thread number.
- The scaling is achieved by decomposing the computational domain into patches used for balancing the computational load. Patches can be activated or deactivated at run time to acommodate complex simulation domain boundaries as is shown below:

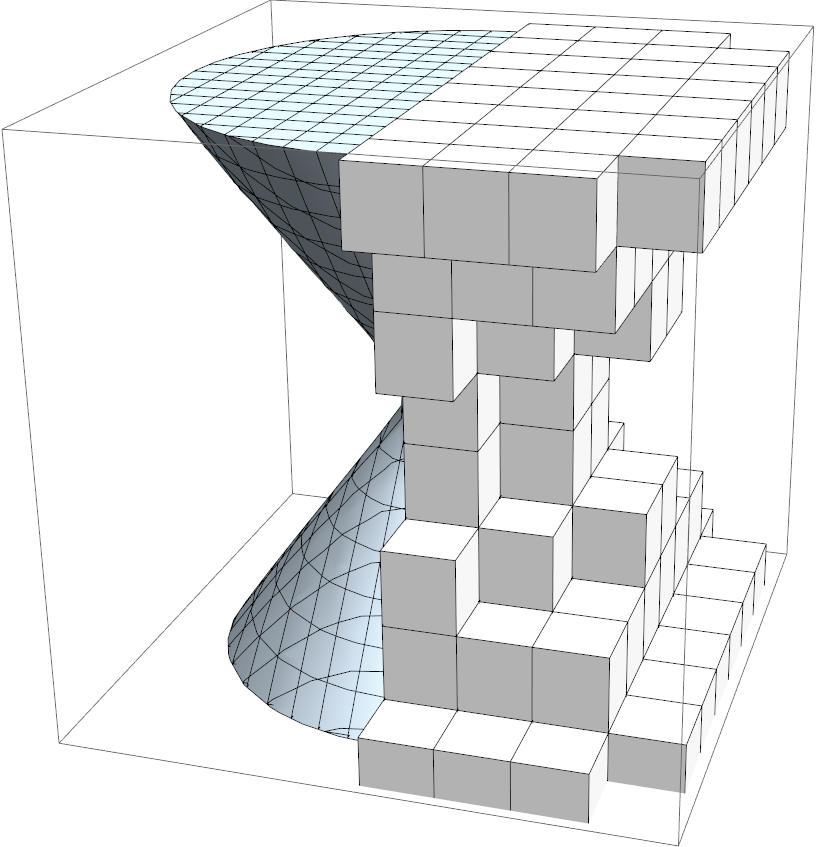
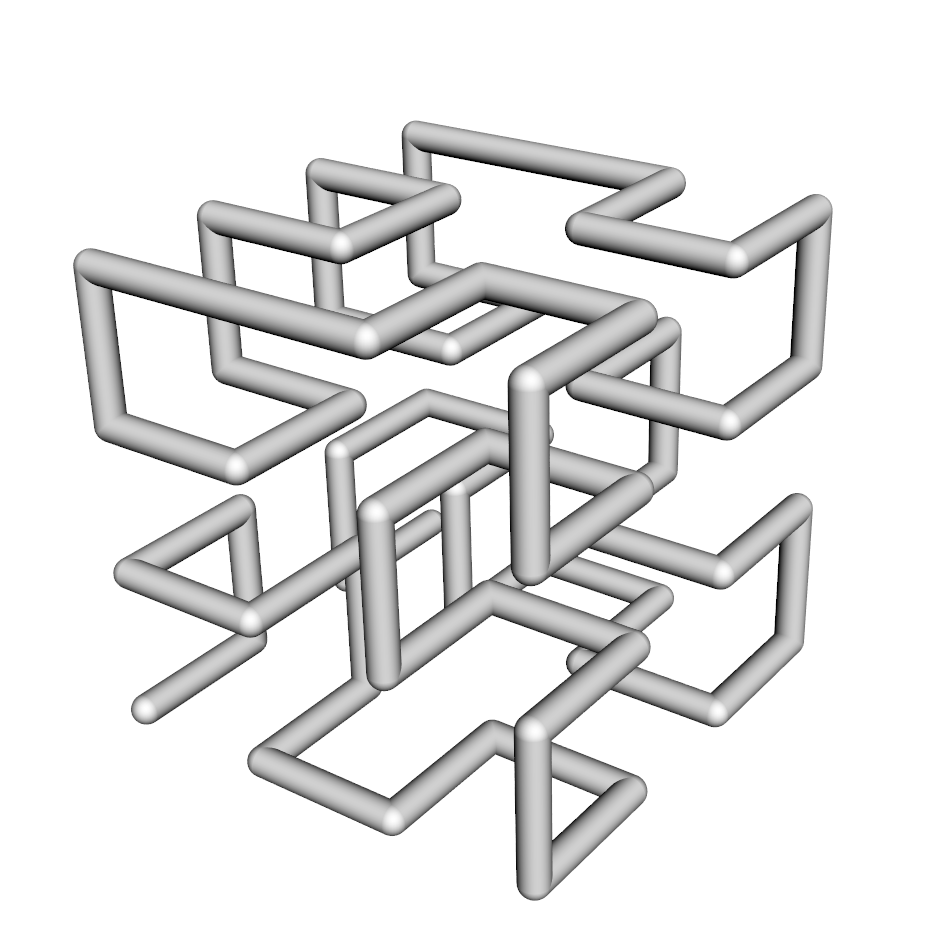
- For optimal load balancing Hilbert-Peano space filling curves are used. Multi-patches are shifted along the Hilbert-Peano curve in an effort to achieve balanced load distribution across the computing platform. Nodes can host variing numbers of multi-patches depending on the load of individual patches for overall even load distribution. A Hilbert-Peano curve in 3D for the colored cube above is illustrated below:
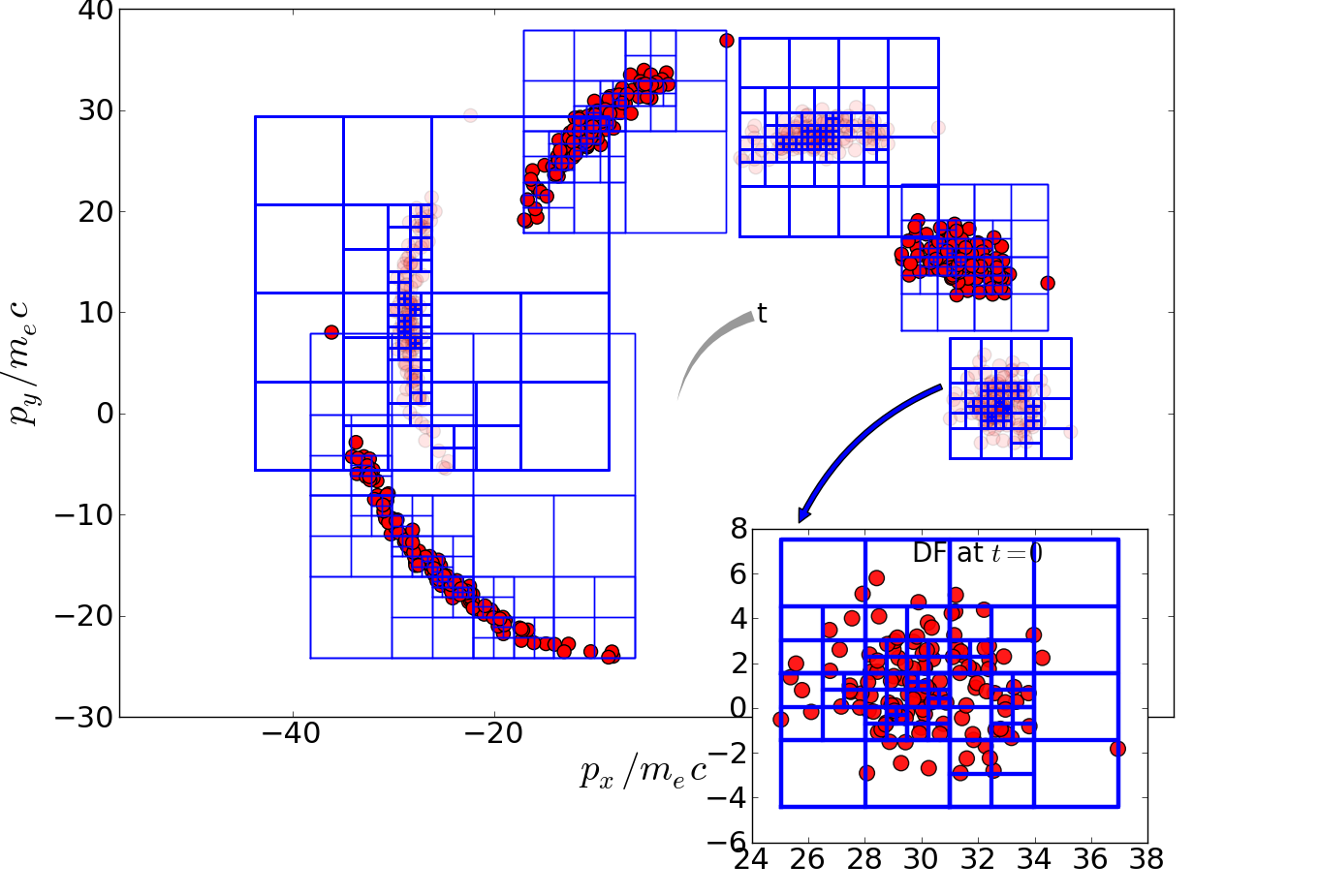
- To simulate multi-scale problems the code is capable of Adaptive-Particle-Refinement (APR). Depending on statistics requirements APR creates or destroyes quasi-elements. APR insures that always sufficient quasi-elements are available for an appropriate signal to noise level (SNR). APR is capable of splitting and merging quasi-particles without generating artificial divergence while at the same time conserving mass, momentum and energy of the initial particle distribution after merging or splitting:
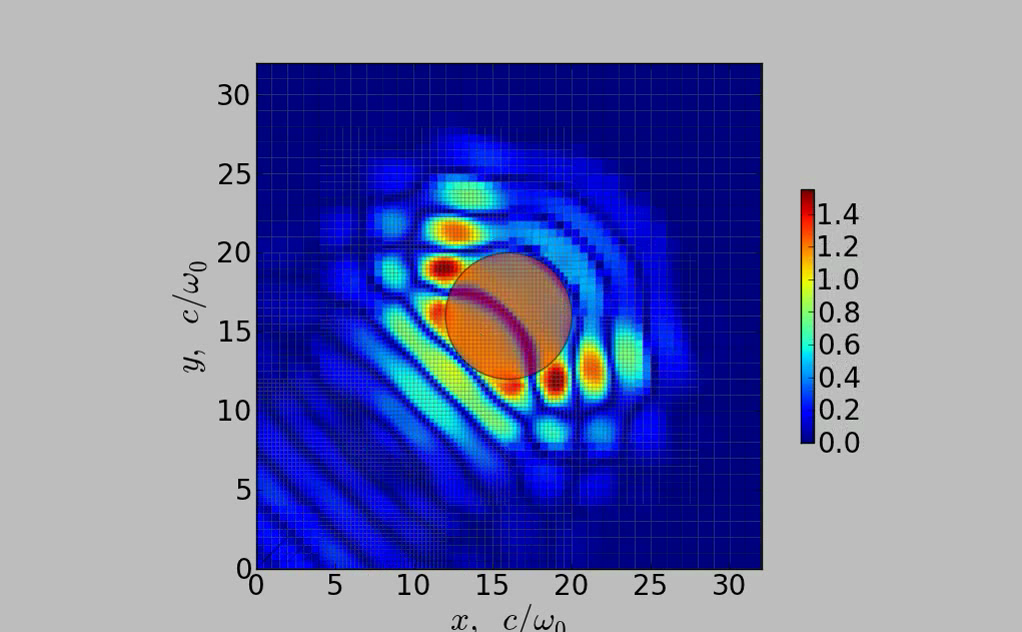
- Future versions of the PSC will make the method of Adaptive-Mesh-Refinement (AMR) available. AMR requires non-uniform meshes or multi-grids. The figure below shows the propagation of a laser pulse on the AMR domain. The numerical scheme developed in our group residing on the multi-grid does not show any reflection at grid resolution boundaries in the AMR domain. We have developed an AMR solver for Maxwell fields. AMR simulation results are show below:
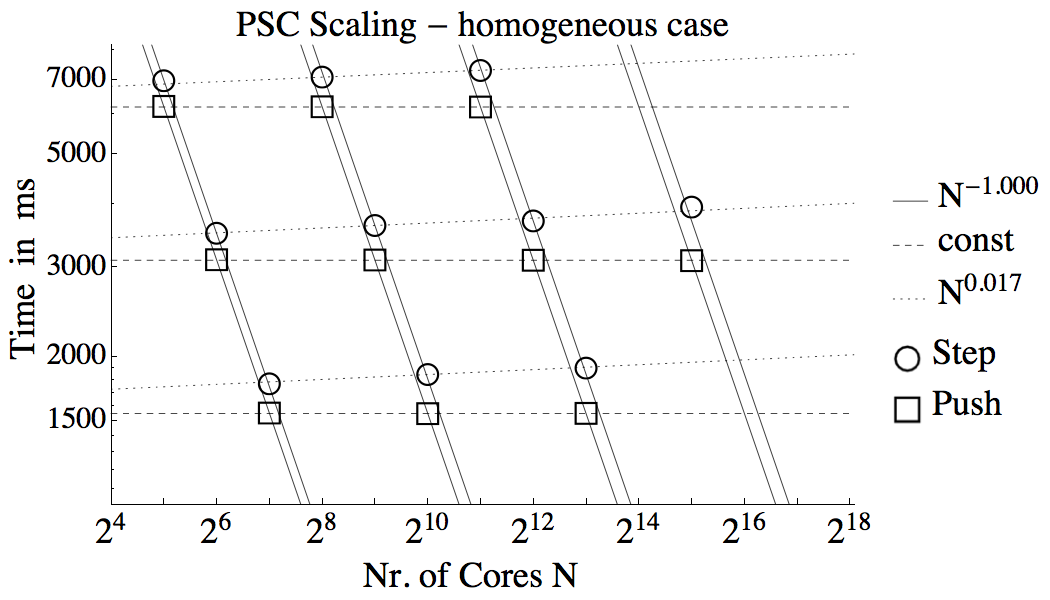
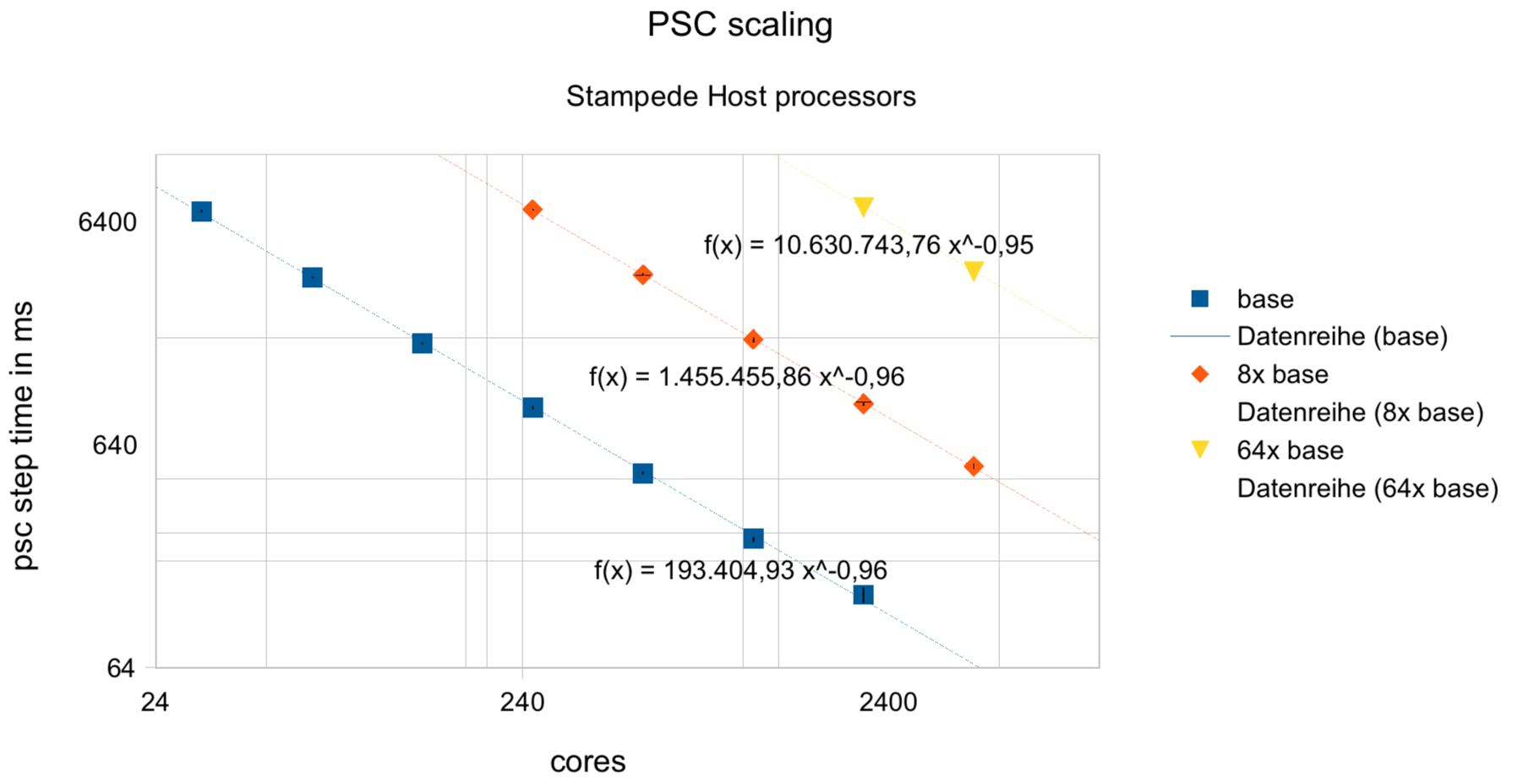
- The figures below show the linear performance scaling of the PSC code with node number. To achieve linear scaling load balancing by shifting multi-patches along a Hilbert-Peano curve is required. The load balancer respects the limits on the available memory per node. As soon as the computational load runs out of balance there is a significant performance improvement by load balancing. The plot below show performance scaling achieved with the PSC on Stampede at UT Austin:
- The plot below shows tha performance scaling of the PSC on SuperMUC. On Stampede and SuperMUC the PSC scales almost perfectly with node number. Near perfect strong and weak scaling is observed: